Four Challenge Tracks
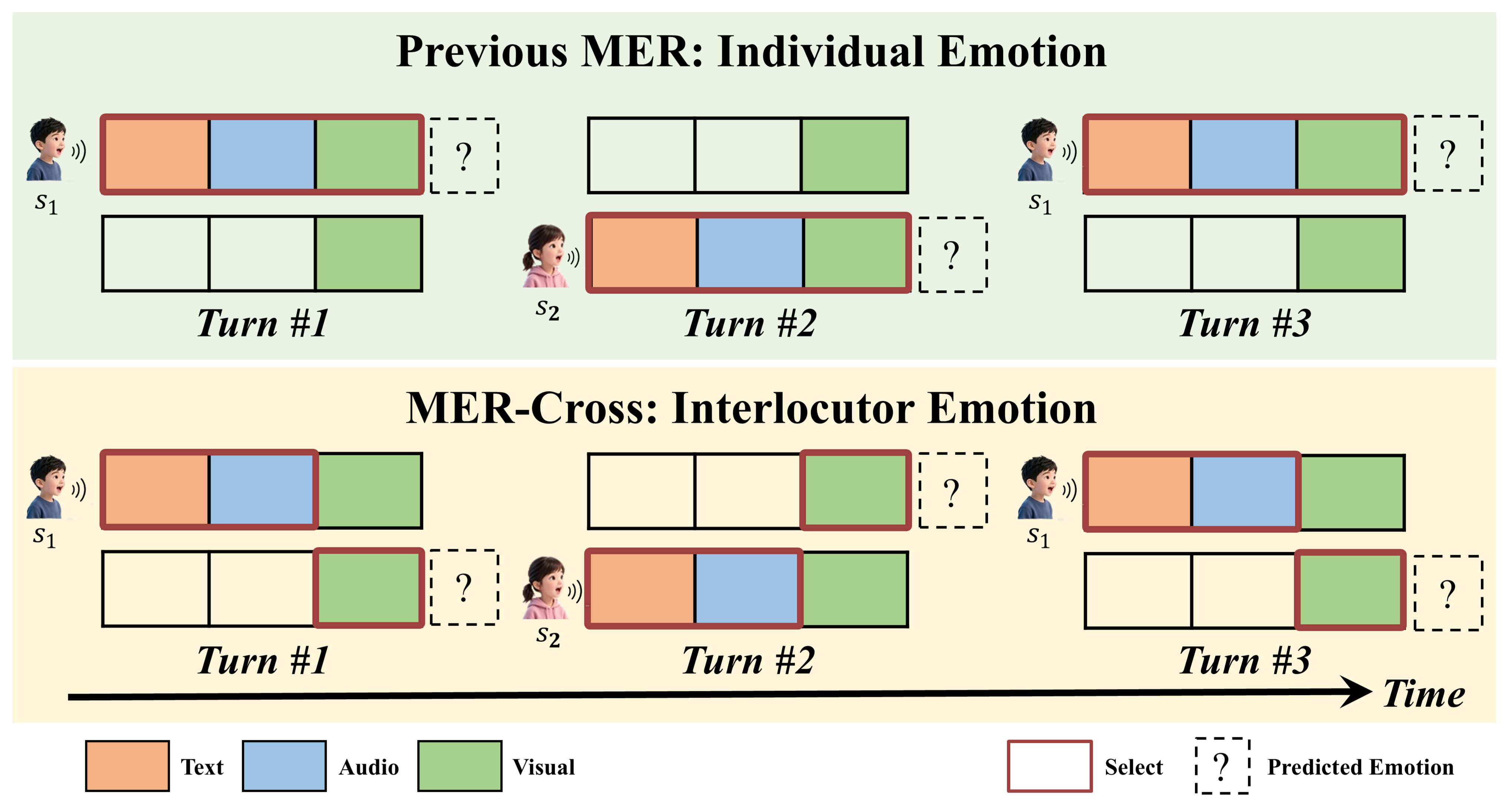
MER-Cross: Interlocutor Emotion
A newly introduced track that shifts focus from individual scenarios to dyadic interactions. When speaker s₁ is talking, MER-Cross targets the emotion of the listening s₂ (interlocutor) rather than the speaker, enabling capture of both sides of a conversation.
MER-FG: Fine-grained Emotion
Human emotion extends far beyond basic labels. In this track, participants can predict any number of emotion labels across diverse categories, expanding recognition scope from basic to more nuanced emotions.

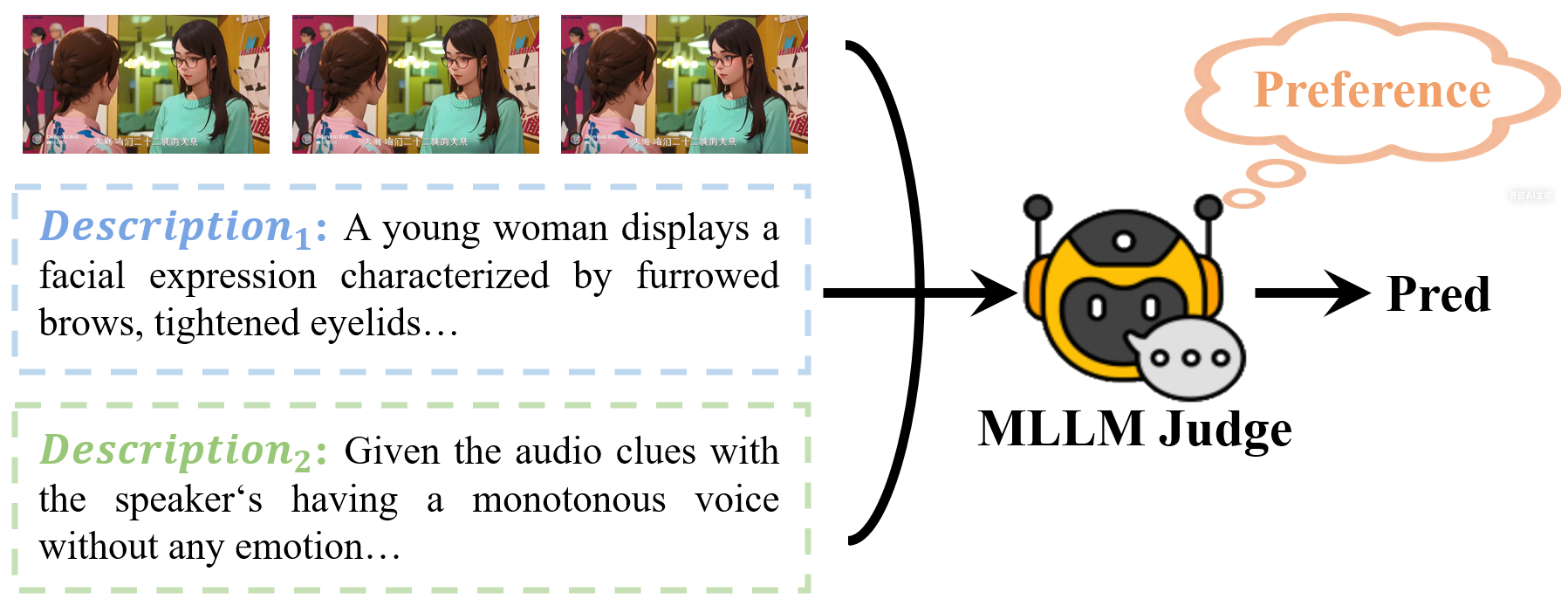
MER-Prefer: Emotion Preference
A newly introduced track predicting which of two emotion descriptions is preferred by human annotators for a given video — a critical component for training reward models in emotion understanding.
MER-PS: Physiological Signal Emotion
Shifts emotion recognition from observable behaviors to physiological evidence. Using synchronized EEG (64-ch, 1000 Hz) and fNIRS (51-ch, 47.62 Hz) signals from 30 participants watching 15 emotion-eliciting video clips.
A key feature is real-time dynamic emotion annotation — subjects continuously report valence and arousal via joystick at 1 Hz. The goal is to estimate the valence–arousal trajectory from brain signals.
Resources & Submission
[1] Zheng Lian et al. MER 2023: Multi-label Learning, Modality Robustness, and Semi-supervised Learning. Proceedings of the 31st ACM International Conference on Multimedia, 2023.
[2] Zheng Lian et al. MER 2024: Semi-supervised Learning, Noise Robustness, and Open-vocabulary Multimodal Emotion Recognition. Proceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing, 2024.
[3] Zheng Lian et al. MER 2025: When Affective Computing Meets Large Language Models. Proceedings of the 33rd ACM International Conference on Multimedia, 2025.
[4] Zheng Lian et al. Explainable Multimodal Emotion Reasoning. arXiv:2306.15401, 2023.
[5] Zheng Lian et al. OV-MER: Towards Open-Vocabulary Multimodal Emotion Recognition. Forty-second International Conference on Machine Learning (ICML), 2025.
[6] Zheng Lian et al. AffectGPT: A New Dataset, Model, and Benchmark for Emotion Understanding with Multimodal Large Language Models. Forty-second International Conference on Machine Learning (ICML), 2025.
[7] Zheng Lian et al. EmoPrefer: Can Large Language Models Understand Human Emotion Preferences? International Conference on Learning Representations (ICLR), 2026.
[8] Zheng Lian et al. AffectGPT-R1: Leveraging Reinforcement Learning for Open-Vocabulary Multimodal Emotion Recognition. arXiv:2508.01318, 2026.




















